


Как текст превращается в понятный для модели сигнал
Первый этап — преобразование текста в числовую форму, с которой может работать алгоритм. Для этого используются языковые модели, обученные на больших корпусах текстов. Они разбивают запрос на токены (слова, части слов, спецсимволы) и превращают их в векторные представления — наборы чисел, отражающих значение и контекст.
Важно, что модель анализирует не только отдельные слова, но и их комбинации. Фразы «ночной город» и «город ночью» будут интерпретированы схожим образом, а вот отличия между «фото в стиле реализм» и «иллюстрация в стиле комикс» будут зафиксированы как разные направления в семантическом пространстве.
Далее текстовый вектор передается в генеративную часть системы. На этом этапе модель уже не работает с буквами, а оперирует абстрактным «смысловым слепком» запроса. Задача — связать его с визуальными представлениями объектов, сцен, фактур и цветов, которые модель усвоила на этапе обучения по парам «описание–изображение».
Для более точного соответствия используются механизмы внимания: алгоритм на каждом шаге генерации «смотрит», какие части текста сейчас важнее. Когда формируются, например, фон и освещение, сильнее учитываются слова про время суток и атмосферу; при дорисовке персонажа акцент смещается на описания внешности, одежды и эмоций.
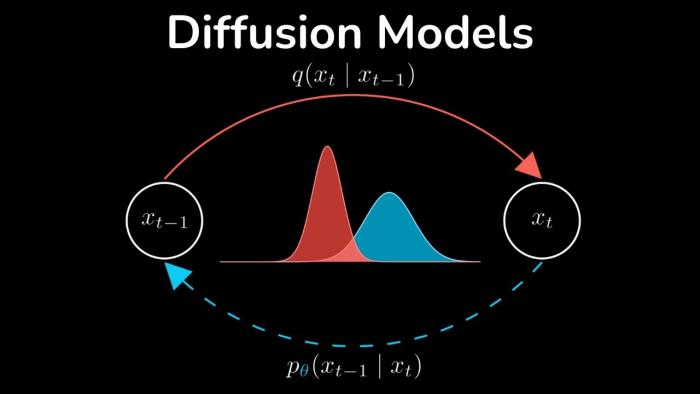
Генеративный процесс: от шума к осмысленному изображению
Сами изображения создаются в один или несколько этапов, в зависимости от архитектуры модели. Распространенный вариант — диффузионные и латентно-диффузионные модели.
Принцип работы диффузионного подхода можно описать так. Во время обучения к реальным изображениям последовательно добавляют шум, постепенно разрушая структуру. Модель учится по зашумленной картинке восстанавливать исходное изображение, опираясь на текстовое описание. На этапе генерации все происходит в обратном порядке:
- Алгоритм стартует с почти полностью зашумленного представления (по сути — абстрактного «шума»).
- На каждом шаге модель убирает часть шума и немного уточняет структуру будущего изображения, опираясь на текстовые векторы.
- Механизм внимания связывает конкретные фрагменты текста с локальными участками картинки, помогая разместить объекты, задать стилистику и освещение.
- После заданного числа шагов получается конечное изображение, которое затем может быть увеличено, доработано или перегенерировано.
В латентно-диффузионных моделях процесс протекает не в пиксельном пространстве, а в сжатом латентном представлении. Изображение сначала кодируется в компактный набор признаков, генерация идёт именно в этом пространстве, а затем результат декодируется обратно в картинку высокого разрешения. Это ускоряет работу и позволяет получать более детализированные «фото из текста» на бытовом оборудовании.
От качества промта до реализма результата
Точность преобразования описания в изображение зависит не только от архитектуры модели, но и от того, как сформулирован запрос. Алгоритм опирается на статистику: он сопоставляет текст с теми сценами и сюжетами, которые чаще всего встречались в обучающем наборе. Поэтому общие формулировки приводят к усредненным результатам, а более детальные промты задают для модели более жесткий «коридор» вариантов.
Часто рекомендуется учитывать несколько факторов:
- Объекты и связи между ними — кто или что изображено, в каком взаимодействии.
- Сцена и окружение — фон, интерьер или пейзаж, дополнительные элементы.
- Стиль и формат — фото, иллюстрация, 3D-рендер, живопись, тип ракурса.
- Свет и атмосфера — время суток, источник освещения, настроение кадра.
Дополнительно влияют параметры генерации: количество шагов диффузии, сила привязки к тексту, уровень случайности. Увеличивая число шагов, можно получить более детализированное изображение, а играя с «силой текста» — балансировать между точным следованием описанию и свободной художественной интерпретацией.
При этом сохраняются и ограничения. Модель может неправильно интерпретировать редкие термины, путать сложные сцены с большим количеством объектов, искажать пропорции. Это следствие того, что алгоритм опирается на вероятностные закономерности, а не на физическое понимание мира. Поэтому на практике часто используют несколько итераций генерации и уточняют промт по результатам первых попыток.
Преобразование описаний в изображения — это не магия, а последовательный процесс: текст переводится в числовое представление, связывается с визуальными признаками, а затем через серию шагов из шума «прорастает» осмысленная картинка. Чем лучше пользователь понимает принципы работы текст-к-изображению, тем эффективнее он может управлять результатом: выбирать формулировки, задавать стиль, контролировать детализацию и осознанно использовать нейросети как инструмент для создания убедительного визуального контента.
Источник: https://avalava.ai/

